Visualisation Support for Identity Networks¶
for Identity Networks¶
Work in progress
For a single real world entity , there exists in the digital world multiple representations. In the Semantic Web, these representations are called resources and are materialised using Internationalised Resource Identifiers also known as IRIs. To illustrate such representation, Rembrandt Harmenszoon van Rijn the painter is https://www.wikidata.org/wiki/Q5598 in Wikidata, http://vocab.getty.edu/ulan/500011051 in Getty, https://viaf.org/viaf/64013650 in VIAF1, and http://dbpedia.org/resource/Rembrandt in Dbpedia. Like this, co-referents of Rembrandt are identified across these for datasets and many more. Certainly, this feature of bridging resources across datasources brings us closer to a more comprehensive view on the real-life entities under scrutiny rather than the information available in a single or fewer datasources. Taking advantage of this feature requires one to find sets of resources (co-referent) that together point to the same and unique real world entity across datasources of interest. Such practice is the task of entity matching algorithms during which matching entities consists in creating identity links – pairwise relationships between co-referent resources – based on their computed matching degree of confidence using often times the owl:sameAs predicate [Raad2018, Achichi2017, Volz2009]. In this scope, the set of co-referent resources connected through such identity relationships forms what we denote in this paper as an Identity Link Network (iln) and define as an undirected network of nodes denoting resources or IRIs, where edges representing identity relationships between nodes may or may not come with weight, which stands as a degree of confidence between matched resources. In this work, the focus is rather on weighted undirected identity networks as illustrated in Fig. 1. It provides a real-life example of an iln bridging four datasources (see Section XXX) depicted in the four node colours. The plain black lines denote full confidence according to the underlying matching criteria, in contrast with dotted red lines that denote less confidence.

Depending on the data at hand, finding co-referents can turn out either trivial or complex. Across real-life data however, this often appears to be a rather complex task [Raad2019], leading to incorrectly stated co-referents. Clearly, it is agreeable that where there is a high likelihood of error (see the motivation section), there is a prominent need for correction as such error could lead to misleading analysis, wrong conclusions, bad-decision making, etc. From this perspective, a raising concern can be translated into “how to facilitate the detection of errors?”. In other words, “how to efficiently validate links?” or “how to ensure that the resources in an iln indeed are co-referents?”. Answering this specific question is philosophically complex [Frege1952], but out of the scope of this paper. A simple solution that we adopt here is that a correct iln is a set of resources pointing to the same real-life object.
On the one hand, identity links are crucial for a successful integration of Semantic Web data. As such, it is paramount that false positive links are not part of the constituent body of identity links granting a successful integration. On the other, results of real-life entity matching bring about statement (links) uncertainty. Although this uncertainty does not always make a statement untrue, it does nonetheless give rise to the need for statement verification. See Section 1 for more details.
>>>Related work does this, this and that to support detection of false positives. We instead propose to use the weight as means for regrouping potentially strongest co-referents to promote a strategy to incrementally evaluating/eliminating the weakest links… ???We evaluate the regrouping results by re-doing a community detection. As future work, to make this feature available in a tool so that the incremental strategy can be evaluated from users’s perspective.
We argue that a strategy for investigating an identity network is by process of incremental elimination with visual aid that exploits both the structure of the ILN and the weight of its links. By doing so we highlight the weakest links as bridges (if any), which constitutes a potential indication of disagreement, and, if necessary, further investigate the grouped co-referents. We motivate this choice with two simple points:
-
Size The impracticality of manual correction is of the essence as data are getting larger by the years with the event of better technologies and the need for more digitisation. When it comes to entity matching, a consequence of large data is the discovery of a large amount of links mingled with a surplus of false positives. Mind you, it does so even more given the low quality of input data for matching approaches. But, this is not all! The goal of entity matching in the Semantic Web is data integration, meaning that the concern is likely more ambitious than the discovery of links within a single data-source or even just two data-sources, but among several sources that often describe different yet complimentary views on the same entities. In this setting, the size and the number of derived iln also increase.
-
Automation Even though automation can be used, it too comes with imperfection and uncertainty as the complexity of a validation process itself is certainly not exempt from errors if automated. Ultimately, the most reliable solution is manual validation, though also not exempted from error. Opting for a semi-automated approach (human-computer interaction) however may combine benefits of both approaches.
Thereof, our contribution to the semi-automation of identity-statement verification is the visualisation of the resulting networks in a meaningfully summarised structure where weighted bridges are gradually highlighted as the size and look of identity networks can reveal daunting. For such purpose and in the context of entity matching, we argue that the weight of a link can help in a meaningful summarisation of ilns.
1. Background¶
An iln can be constructed automatically (through entity matching algorithms) or manually. Either way, ilns may have their quality compromised by the inclusion of false positives (i.e. resources that are in the same iln but do not denote the same real-world entity). An ideal identity link network (iln) can be expressed as a full mesh network structure, meaning that if a real-life entity has n co-referents in m datasets, all the possible undirected connections among them are captured (with high-confidence), leaving one with no much to investigate. However, with real-life data, this is a different story as a high-confidence full mesh structure is not always observed. Instead, partial meshes are the ones often observed (e.g. due to incomplete knowledge), which may include one or more bridges, indicating potential identity disagreement. In practice, implying identity correctness from a full mesh network is not always possible (as vagueness and uncertainty may be at the core of the network generation), let alone from a network which includes bridges. This may suggests that identity networks generated from real-life data require investigation.
The underlined need for further validation is indeed strengthened by the high likelihood of imperfect matching results given the use of real-life data. Here, we highlight a few reasons, either obvious or hidden.
-
Obvious cases in which false positives are more likely to happen are, for example, (a) the low quality of data. Often enough, data come with several issues that may impair the matching process. For example, it can be of low quality; it can be incomplete in the sense that entities to disambiguate are not described at the same level of granularity; it may contain inconsistencies / errors such as misspellings, spelling variances, contradicting values; or yet it may rely on different calendars, among others. Other cases include (b) the problematic context-independent semantics of owl:sameAs or (c) the inadvertent misuse of the owl:sameAs predicate as highlighted in [Halpin2010], and (d) the inadequacy of matching algorithms to tackle the data-sources at hand.
-
In less obvious cases, false positives result from issues that need addressing during the matching process. These issues can be categorised as ways of (i) modelling how to compare the values of entities’ properties, and (ii) inferring co-reference or identity.
- (i) The modelling of ways to find supporting evidence for isolating potential matching candidates is crucial to inferring identity for a pair of resources. In this endeavour, some approaches may produce discrete / precise results while others may produce continuous / vague results. For example, comparing if two resources have the same name can be precise if exact-match is the method of choice, but the same comparison can also be evaluated with vagueness if a similarity approximation method is chosen instead. In the former case, comparing (Alessandra, Sandra) results in false or 0, while in the second approach the comparison result-space is in the interval [0, 1] to describe the degree of truth such that (Alessandra and Alexandra) is more “true” than (Alessandra, Sandra), which is more “true” than (Alessandra, John). As expected, this too is likely to lead to incorrect matchings. Although the precise modelling produces more reliable results, it appears limited [Schoenfisch2014] as unable to cope with vagueness and thereby reducing the chance of finding all correct matches, leading to an increase of false negatives. On the other hand, although the modelling of vagueness opens a range of possibilities, it also increases the injection of false positives (noise).
- (ii) Properly inferring identity for a pair of resources depends not only on how well the aforementioned precision versus vagueness issue is addressed as computed evidence (i) but also on how strong is the discriminating power of combined evidence to infer identity agreement (co-referents) or disagreement between a pair of entities. This is often worsen by data incompleteness: the less complete the less discriminative. For example inferring that entities and are the same whenever their share similar names and place of birth is a low discriminating criteria as there exists multiple entities materialised as Jan Jans and born in Amsterdam. Mind you that here too, the solution space of such comparison is a sliding scale within the unit intervbal [0, 1] corresponding to a degree of confidence known as uncertainty. This means that inferring if a resource Jan Jans born in Amsterdam is co-referent of another resource Jan Janzoon born in Amsterdam is either true or false (not vague) begs for a level of confidence that reflects both the vague comparison of their names (almost the same) but also the lack of strong discriminating criteria to be sure about the inference.
2. Related work¶
A considerable body of scholars in the field of community detection have organised nodes on the belief that the more edges a group of node share the greater the likelihood that they are similar [Blondel2008, Newman2006].
3. A Visual Vocabulary For ILNS¶
As a network increases in size, it gets harder to make sense of its hidden structure, its visualisation becomes difficult and rendering the data to display becomes expensive as the network resembles a meaningless cloud of points [Alhajj20014].
For an intuitive understanding of a graph’s hidden structure and for reducing the amount of data to render, we display a compressed version of an original graph based on the weight of its links. This section presents the basic vocabulary for interpreting such a compressed visual representation of a network based on the weight-annotation of its links. Details on how to construct such a network and its use to detect identify communities is provided in Section XXX.
3.1 Compact with Satellites¶
The term compact node is defined as a compressed representation of linked-nodes where the link(s) share the same weight-annotation. Such an annotation is perceive as an annotation-pattern. In this context, the shared annotation-pattern is the weight-annotation with the highest strength.
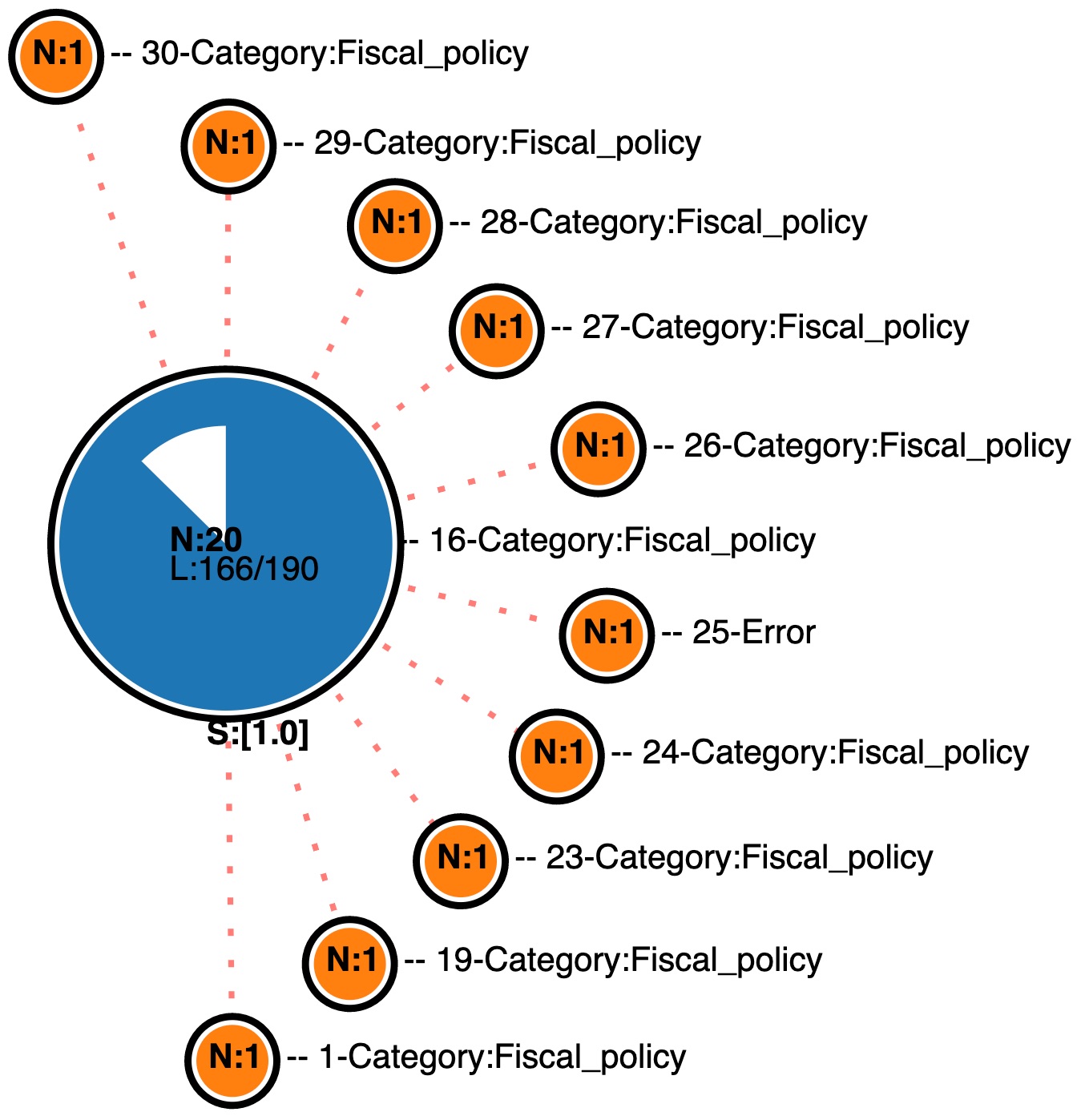
A compact node – the blue node in the figure on the right – is given a color, a label (one of the labels of the nodes it represents) and its size is proportional to the number of nodes compressed. It also comes with two additional numerical data: N is the number of compressed nodes and L shows the number of links in the network as a fraction of all possible links. In addition, the main color of the node is overlaid by a white circular color indicating the proportion of missing links, indicating the ``incompleteness’‘ of the sub-network represented by the compact node. S indicates the shared weight-annotation.
A satellite node – orange nodes in the figure – is a single node that connects to one or more compact nodes and do not share a pattern. Such node is also given a color, a label, a fix size where N is always 1 and no L.
Fig. 1 illustrates an identity network of 30 nodes connected by 176 links annotated with strength value of 0.5 or 1 (discrete value annotation). The compact node coloured in blue compressed 20 nodes (N:20) that are all connected with links of strength 1 indicated by S:[1.0]. The white overlay color indicates the proportion of missing links and the number of exact missing links can be computed using the numeric data provided by L:166/190. In this case, 24 links are missing. The other 10 nodes in the figure are viewed as first level satellites of the compact node. In this example, the compressed representation reduces the number of initial nodes to be displayed from 30 to 11 and and the label pairs from 166 links to 10, showing the strength of our compressed visualisation.
3.2 Community mode¶
In community mode, satellites are not allowed because they are direct neighbours of a compact node and are not network themselves (N=1). Whenever such a phenomenon occurs, in community mode, the compact node pulls in all satellites whenever they exist. It then updates accordingly its size and its counts of child-nodes and links. Finally, it turns its original plain black border into a dashed border to indicate the existence of satellites.
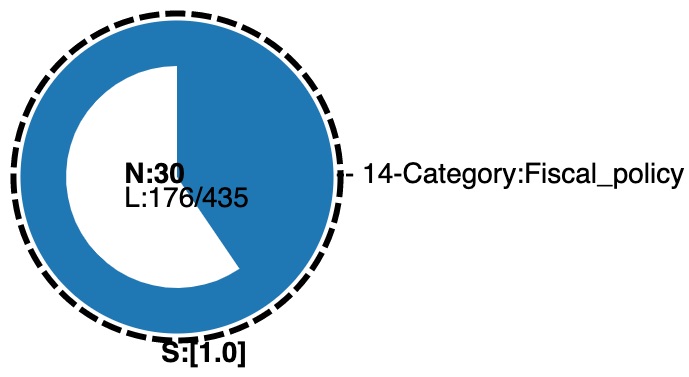 Fig. 2 shows Fig. 1 in a community mode. It high-lights that in the original network of 30 nodes, no secondary subnetwork exists, as all its satellites got pulled in. This is reflected in its dashed border as well as in its child and link counts, in contrast with the information displayed in Fig. 1.
Fig. 2 shows Fig. 1 in a community mode. It high-lights that in the original network of 30 nodes, no secondary subnetwork exists, as all its satellites got pulled in. This is reflected in its dashed border as well as in its child and link counts, in contrast with the information displayed in Fig. 1.
3.3 Interlink¶
An interlink is a compressed link that (i) connects a satellite node (N=1) to a compact node (N2) or, (ii) connects two compact nodes. When links are being compressed, the thickness of the interlink is proportionally increased. With quantitative weight-annotation in the interval ]0, 1], (i) dashed red links are of value ]0, 1[, (ii) black plain lines are of value 1, and (iii) the weaker the strength, the more sparse is the dashed red link.
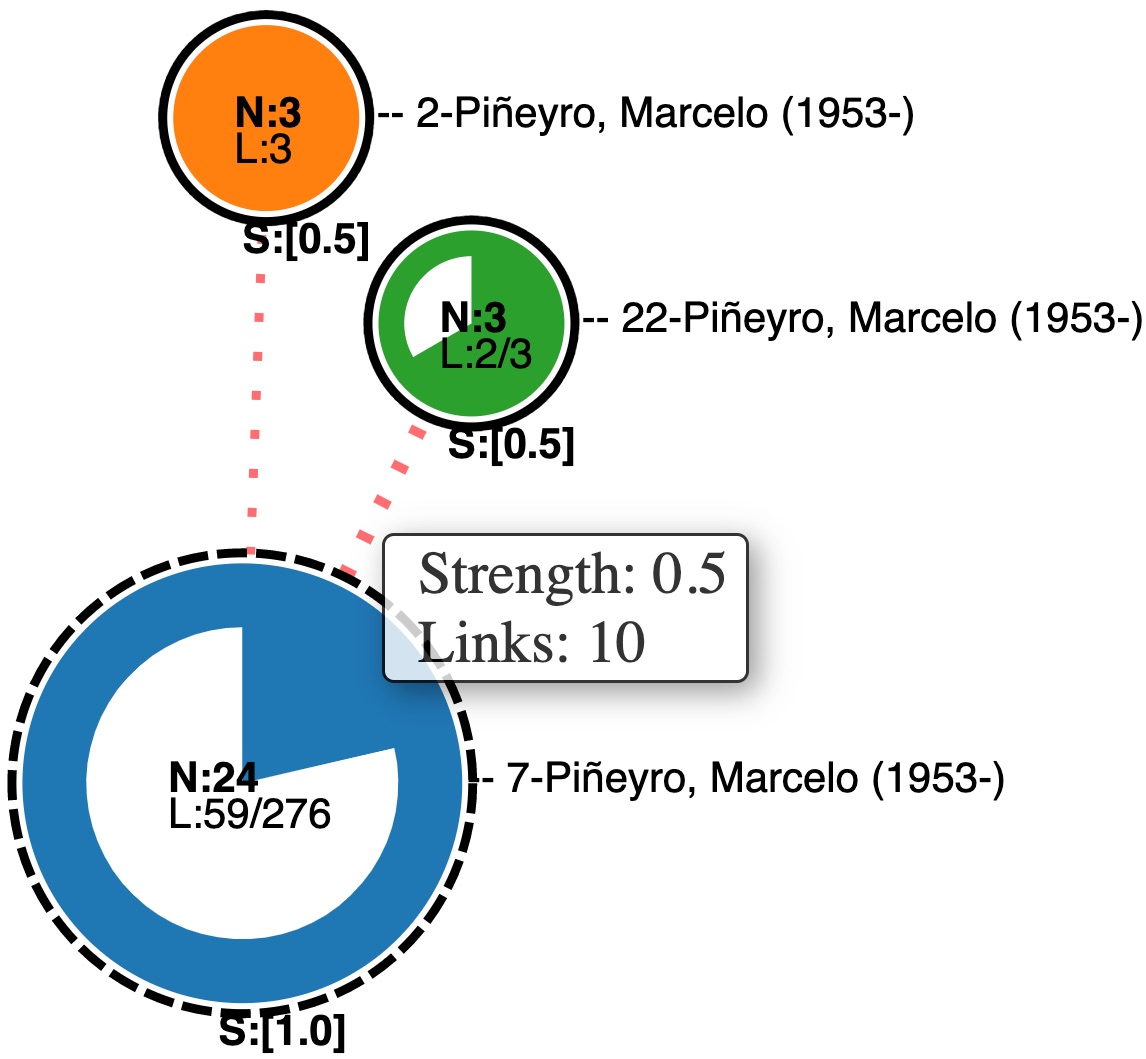 The Figure on the right illustrates three interconnected communities: Orange (north), Green (north-east) and Blue (south). Orange and Green are small, composed of 3 children each and no satellite (no dash border). While Orange is fully connected (L=3), Green has one missing link indicated by the white overlay color and L=⅔. Blue, the biggest community node is of 24 children. It connects to Orange using 1 interlink and connects to the Green using 10 links hinted by the thicker interlink. Here, an initial network of of 30 nodes and 75 links is now reduced to 3 nodes and 2 links.
The Figure on the right illustrates three interconnected communities: Orange (north), Green (north-east) and Blue (south). Orange and Green are small, composed of 3 children each and no satellite (no dash border). While Orange is fully connected (L=3), Green has one missing link indicated by the white overlay color and L=⅔. Blue, the biggest community node is of 24 children. It connects to Orange using 1 interlink and connects to the Green using 10 links hinted by the thicker interlink. Here, an initial network of of 30 nodes and 75 links is now reduced to 3 nodes and 2 links.
4. Weight-Based Identity Agreement¶
Section 3 presents a visualisation approach for large networks by grouping nodes that share the same strength (possibly grouped by interval) as a single compact node. It is intended to efficiently visualise Identity Link Networks with the goal of validation. In this section, we first elaborate on the supporting rational for opting for the merging / compression of nodes in an identity network based on the weight of their examined common traits and then describe the approach.
4.1 Rationale¶
In an identity graph, common traits between pair of nodes have been examined (by expert or computer) and possibly result in an identity link. Ideally, all nodes of an identity graph are co-referent of the same real object. Consequently, these nodes should densely connect, and it should not be possible to separate such an identity graph into identity disagreement groups (for example by applying a community detection algorithm). However, in real-life, the computations of the links of an identity network is subject to errors and incompleteness, leading to the potential inclusion of noise (false positives nodes and links) and the absence of numerous true positive links.
It has been shown in [Raad2018, Raad2020] that community detection algorithms can be used to detect sub-groups in a candidate identity link network that points to one or more real world objects. In such community detection approaches or related tasks such as graph compression / summarisation, nodes merging is the shared commonality. Only, the rational for the merge differs. Some merging technics ensure that decompression is optimised [Toivonen2011], some focus on link density [xxx] while others focus on structure conservation [Shen2010, Jin2018]. In this paper, the rational for merging nodes in the context of identity link network and link validation revolves around the meaning of a link and of its weight as the belief is that the combined meaning these two shed light on a different merging perspective. To understand this, let take a look at the network of eight nodes in Fig. XXX. First, suppose that Fig. XXX illustrates a social network of friendship. Although nodes 1 and 2 share a friendship, the rest of the friends of 1 do not interact with 2. The same goes for the friends of 2. Furthermore, while some of the friends of 1 know each-other, the opposite is observed with 2 meaning that his friends interact with no one else but him. Interpretation wise, these observations may imply that 1 and his friends (except 2) share more traits than 2 does with his friends and that 1 and 2 may be friends for something that only the two of them share. Strengthening the interpretation by also including the interpretation of the weights will mainly highlight the quality of friendships but will not change the intuition of the presence of two groups of friends. In this first scenario, the meaning of a link allows the intuition that the density of the links may indeed suggest two subgroups of friends and may also suggest a need for structure conservation. However, if we now assume that Fig. XXX denotes instead a network of an identity agreement, it is not necessarily the case that two sub-networks can be inferred (only one instead) because all the nodes are supposedly collapsable into a single one as they are in this new context instantiations of the same real world object. In other words, in an identity network, a link implies that connected nodes can be merged as they are co-referent while the link’s weight comes as a merging countermeasure that emphasises the confidence for indeed merging connected nodes if needs be. It follows that, in an iln, nodes that share the same weight (or weight interval) are also more likely to cluster together. With this rational, we now introduce in the next section how to proceed with merging nodes based on shared weight.
4.2 Approach¶
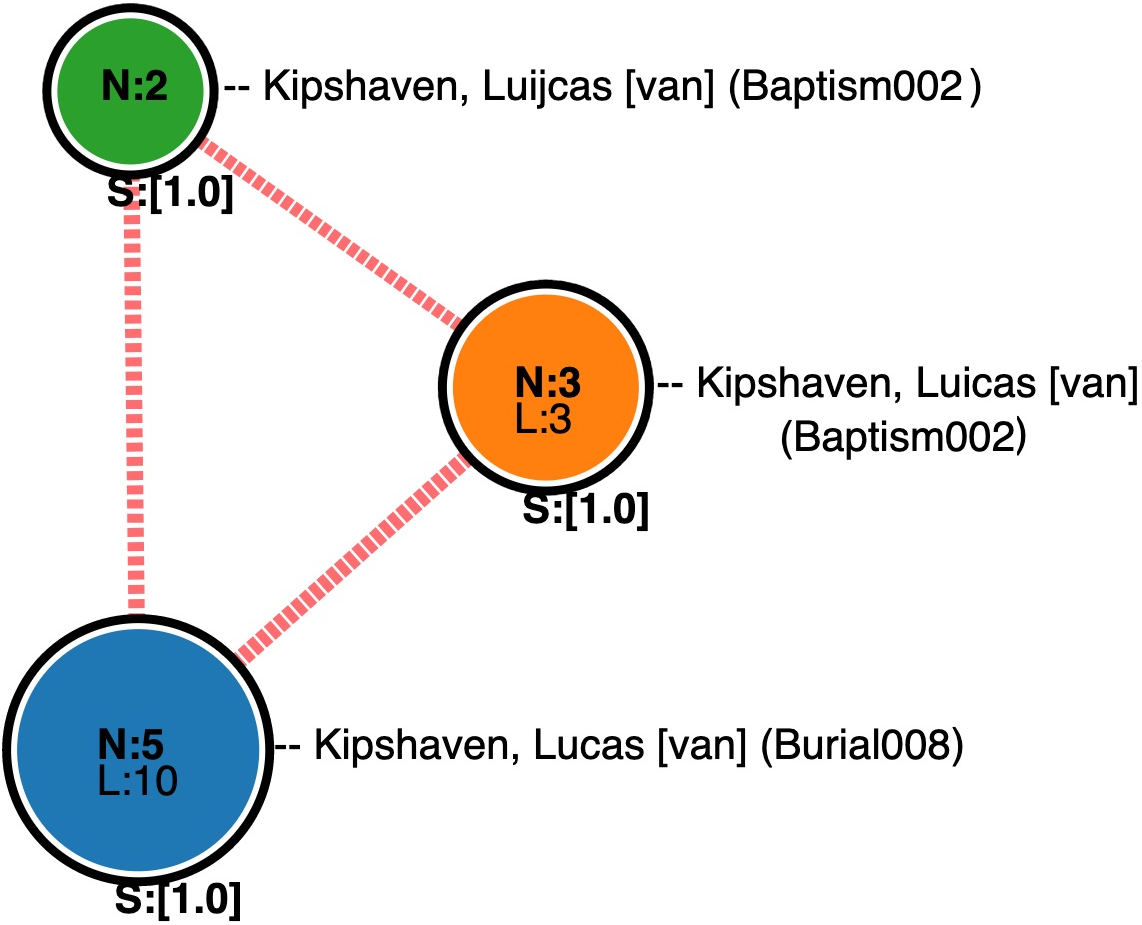
We use Fig. 1, a real-life example of an identity network of 10 nodes and 42 links to illustrate the heuristic behind the proposed approach. Here, the score of a link is computed on the basis of name similarity and the network connects instances of “Kipshaven Lucas” from four datasets (Burial -two red nodes-, Marriage -one blue node-, Baptism -six green nodes- and Ecartico -one orange node-) using plain black links (S=1) or red dotted links (S \in ]0, 1]). The weaker the link, the more sparse the red dotted line is.
At first glance, this network structure looks uninformative. However when carefully looking at it, a pattern strikes the eyes: nodes connected with the plane line can be grouped together intuitively. This suggests (i) the use of weight-annotation for grouping nodes and preferably, (ii) starting from the links with the highest weight. So, if we organise the link strengths in Fig. 1 from the most important (S=1) to the least important (S=0.91), pop the highest weighted link in the current iteration and temporarily strip the network from inferior links, we then end up building new sub-networks where all nodes are connected at least once with links annotated with the current strength at each iteration (selection without replacement). For example, if we strip Fig. 1 from all other links but those of strength 1 (plain black lines) at first, we end up with three distinct sub-graphs (respectively of five, two and three nodes) where all the nodes are connected by links of strength 1. Note that, if more nodes remain, this process is repeated following the ordered link’s strength. Once all sub-networks are found, The remaining links can now be used to reconnect the detected sub-graphs as illustrated in Fig. 6.
Using this approach, we can now informatively visualise a large network of 439 nodes and 7,614 links representing the identity network of Obama which is now displayed in Fig. 7 with 264 nodes less. Nevertheless, the approach could be improved for more compression. To address this, our solution is to enable a compact node to swallow its satellites nodes of size 1 by default. Note that this adjustment allows for setting the maximum size of the satellite node (it can be set to 10 instead of 1 for example) to be swallowed on demand. As a consequence, if the size of the satellite is set to x > 1, all compact nodes of size y \in ]1, x] get the status of non valid community. In case a satellite is shared by more than one compact node, which is the case for two nodes in Fig. 6, a tie is broken using progressively2 (1) the compact node with the strongest link to the satellite node; (2) the biggest compact node; (3) the node with the longest URI to be deterministic. We test this idea by comparing its results to a number of renown community detection algorithms on our benchmark and reports the findings in \autoref{sec_pakage}.

[Achichi2017]: Achichi, M., Bellahsene, Z., & Todorov, K. (2017, October). Legato: Results for oaei 2017. In OM: Ontology Matching (No. 2032, pp. 146-152).
[Blondel2008]: Blondel, V. D., Guillaume, J. L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. Journal of statistical mechanics: theory and experiment, 2008(10), P10008.
[Newman2006]: Newman, M. E. (2006). Modularity and community structure in networks. Proceedings of the national academy of sciences, 103(23), 8577-8582.