INTRODUCTION  ¶
¶
Time and again, researchers are presented with problems for which they postulate and test hypotheses in order to provide us with robust explanations for research questions successfully investigated. Often enough, solid explanations for complex problems require exploring a multitude of datasources. This is the case, for example, in domains such as e-science (multiple scientific datasets), e-commerce (multiple product vendors), tourism (multiple data providers), e-social science, digital humanities, etc.
1. Context¶
DATA INTEGRATION. The use of various datasources come at the expense of heterogeneity which obfuscates the path to data integration and thereby hinders accurately addressing complex problems.
Dealing with multiple datasources or data providers highlights the freedom at which providers document facets of the same entity. Indeed, this feature of oriented freedom for entity descriptions can explain, to a certain extent, the inherent difficulty to integrate heterogeneous datasources.
In the Semantic Web, this problem is partially circumvented as any pair of resources can be linked regardless to the uniformity of data representation or vocabulary used, i.e. uniformizing data/schema is not a prerequisite for data integration provided that links between co-referent entities across heterogeneous datasets exist.
RESULT QUALITY. The quality of supporting evidence for accepting or rejecting the hypothesis under investigation for a complex problem greatly depends on the correctness of the links integrating the underlying datasources.
This begs for questions regarding the aboutness and correctness of the links, such as:
-
How to create correct links? More specifically, are there reliable tools or macthing algorithms for linking co-referent descriptions of entity scattered across various heterogeneous datasets? Can different tools or algorithms be combined?
-
How to judge the applicability of links? Can their quality be estimated? Can they be improved, manipulated, visualised for validation purposes, reproduced? More specifically, is there a platform that supports all of the aforementioned concerns?
LINK CONSTRUCTION. Through the years, a number of entity matching tools have been developed and tested.
However, some of theses tools have been developed for specific datasets, while others have limited applicability as they have mainly been tested in domain specific areas using synthetic or simplistic data, generally from at most two datasets. For example, as research in social sciences is increasingly based on multiple heterogeneous datasources, it becomes problematic to be limited to the integration of two datasets.
Furthermore, in practice, the heterogeneity, messiness, incompleteness of data raise the bar higher in terms of entity matching complexity.
In other words, most matching algorithms have been successfully applied in limited and controlled environments. This motivates the need for having the means to (re)use and combine generic matching approaches in order to solve specific problems.
2. Disambiguation Proposal¶
In this document, we present a tool that supports disambiguation over multiple datasets: the Lenticular Lens. As a domain agnostic approach, the Lenticular Lens tool reuses existing matching approaches to allow for the user to reach their goals in ways that alleviates some of the main aforementioned issues:
-
User-dependent and context-specific link discovery.
-
User-based explicit concept mapping.
-
Integration of more than two datasets.
-
Combining entity matching algorithms and results.
-
Structure-based evaluation of identity link networks.
-
Enabling visualisation to support link/cluster validation.
-
Metadata for documenting the link aboutness and enabling reproducibility.
The context dependent link discovery idea developed and implemented in the Lenticular Lens [Idrissou 2017, 2018, 2019] is an extension of the Linkset and Lens concepts introduced by the [OpenPhacts] project in the quests for building an infrastructure for integrating pharmacological data. Our extension and broadening of these concepts enabled us to design and build a flexible tool for undertaking entity disambiguation in a broader perspective.
2.1 Workflow¶
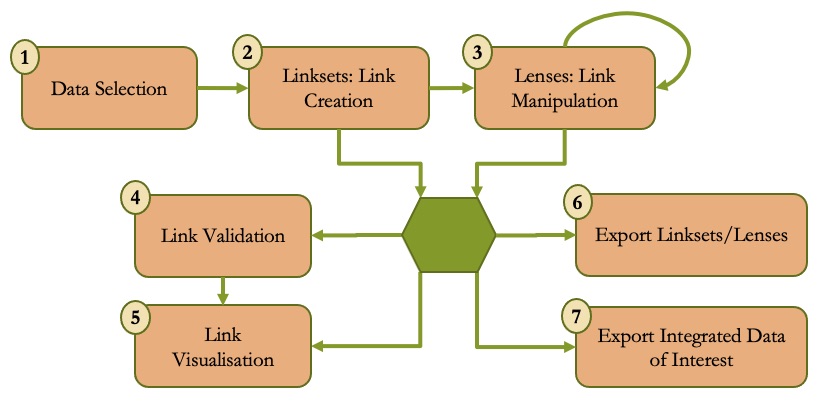
The Lenticular Lens tool offers the users a number of matching-related mandatory and optional tasks to achieve their integration-goals. A workflow depicting possible sequences of executions for those tasks is presented in Figure 1. The process starts with (1) Data Selection and is followed by (2) Link Creation (Linkset). The next optional steps include: (3) Link Manipulation (Lens) for combining previously obtained links; (4) Link Validation for the curation of the obtained links; (5) Link Visualisation to support the verification of the quality of the obtained links; (6) Export Linksets/Lenses to extract the obtained links from the tool and finally (7) Export Integrated Data of Interest to support the user on the extraction of specific descriptions (property values) of integrated entities.
2.1 Dataflow¶
The data used as input to the Lenticular Lens originates from a Timbuctoo Endpoint. The pulled data is then stored and manipulated in PostgreSQL for efficiency purposes. The resultant links generated by the Lenticular Lens tool can be injected back into the Timbuctoo Enpoint, which in turn also enables communication with a SPARQL Enpoint.

3. GUI Menus¶

As a preview of what can be done with the Lenticular Lens tool, we list here the main menus composing the tool and provide a brief description of what can be done in each of the menu.
CONTEXT
This menu aims to specify the scope of the research by giving the researcher the opportunity to remind herself and other users the why of the research. This is done by providing a title, describing the goal and possibly linking the work done in this tool to a published result.
DATA
This menu provides means to:
- Select a GraphQL endpoint so that remote datasources can be located and made available to the user. The default selection is the Golden Agent’s endpoint ;
- Select Datasources and Entity-types from the available list at the remote location so that information can be extracted and integrated in order to conduct an experiment;
- Define restrictions over selected Entity-types.
- Explore data based on pre-defined specifications (Datasource, Entity-type and Property-value Restrictions).
LINKSET
This menu provides means to:
-
Specify the conditions in which to use a matching method or combined matching methods for the creation of a LINKSET, which is a set of links sharing the same specifications.
-
Run the specification i.e create set of links and clusters.
-
Get statistics on the result such as the total number of links found, how they cluster…
-
Validate the resulting links by annotating them with flags such as accept or reject.
-
Export the result in various format.
LENS
This menu provides means to:
-
Specify the conditions in which to combine LINKSET(S) and/or LENS(ES) for the creation of a new LENS, specifically, the use of set like operations (Union, Intersection, Difference, Composition and In-Set) over linksets and lenses.
-
Run the specification i.e combine Linkset(s) and/or Lens(es) and cluster the links.
-
Get statistics on the result such as the total number of links found, how they cluster…
-
Visualise and Validate the resulting links by annotating them with flags such as accept or reject.
-
Export the result in various format.
DATA INTEGRATION
The menu here enables the user to materialise an entity-based integration of her selected datasources for the extraction of information vital to her analysis.
The rest of the manual will discuss
- Terminology
- Link Annotation Ontology
- Algorithms
- Link Construction (it includes the
RESEARCH,DATAandCREATEoptions) - Link Manipulation (it includes the
MANIPULATE, andVALIDATIONoptions) - Link Export (it is about the
EXPORToption) and - Data Integration (it is about the
EXTRACToption)